Target audience: Managers of data science teams
Too many data science proof-of-concept projects (PoC) never deliver business value but end as a slick PowerPoint presentation complemented by an adequate codebase. Even though the business case may be strong and the results promising, many data science projects never reach a production stage. And this is not surprising! Closing the gap between a successful proof-of-concept and a data science product that continuously delivers value is hard. Very hard. As such, I altered my career path from being a data scientist to becoming a data engineer and made it my mission to help companies in pursuit of this ambitious and challenging goal: productionization of data science.
To be transparent, I have worked as a data science consultant for about two years and as a data engineer consultant for a year. In these years, about half of my data projects went to production, while the other half suffered the unfortunate fate described above. In this blog, I highlight my most important learnings in the hope you can take advantage of them. Of course, as I am still very much learning myself, these learnings are no guarantee for success, but rather reflect my perspective on the matter.
In a nutshell, as so many have said before me, in order for a data science project to be successful, I think you should have a good use case! That is a use case with a good business case behind it and which is being supported by both end-users as well as higher management.
Secondly and maybe even more important, I think hiring data engineers and machine learning engineers early in the process is key in making data science successful within your organisation. That is because building the required infrastructure for machine learning products is hard and will take much time and effort. So, if you are committed to reap the benefits from artificial intelligence/data science, I think it is paramount you start building machine learning infrastructure as soon as possible.
Closing the gap between a successful proof-of-concept and a data science product that continuously delivers value is hard. Very hard.
Many businesses invest in data science as it promises many valuable insights into your customers and business processes. Not to mention, everybody else is doing it so you might lose your competitive edge if you don’t start right now. However, developing data science capabilities and products is expensive. There has to be a well-thought-out business case opposite it. With a so-so use case you might get money for a proof of concept or a minimal viable product, but I am quite sure that in the long run, further development will hold.
In one of my projects I worked for a large loyalty company. Together with a team of 6 developers, we were building a recommender engine for a large Asia-based supermarket. Rather than starting with a PoC, we directly worked towards an end product. After six months of development, however, the board of the loyalty company decided recommending products was not part of the core business, i.e. the use case was no longer important for the company. As such, the plug was pulled and the project was stopped.
I think this experience provides us with two lessons:
Thus, whenever you are planning to leverage data science for a certain use case, make sure to work out the business case behind it first and start small. To help you out, try answering the following questions: will an ideal/perfect prediction model actually deliver business value for your use case? And if so, how much? Is the use case aligned with the business and end-users? How much effort does a use case take to work out? If you struggle finding answers to these questions, maybe you can think about fulfilling the analytics translator role within your team.
Besides having a good use case, it is important stakeholders, managers and end-users are committed, not just interested. Too often, I have experienced teams not being met in their needs, whether data or infrastructure related, in which case none of the stakeholders actually took action to resolve any issues. Of course, this leads to extended development time, delaying delivery of any value and deteriorating the belief in data science as a whole. This is bad.
This issue became very clear at another company I worked for, which heavily invested in data science. Together we worked on a variety of projects, some of which in a PoC stage, others heading towards production. We did, however, face an issue: we did not have access to an incoming flow of high-quality data, but had to use data dumps, generated with convoluted one-off scripts. That in itself does not necessarily need to be a problem. Especially in the development phase, using data dumps can help quickly show business value. But, as we had already released a minimum viable product and were heading towards a production stage, we needed this incoming flow of high-quality data for our product to be successful. Together with many other teams we were dependent on a dedicated data lake team for building data pipelines. Unfortunately for us, our data sources were not prioritised over other business critical data sources. From my perspective, this was due to two factors:
These issues together resulted in a delay over a year. In fact, last time I checked the data science product is still not running in production. Since then, I always ask myself: Will someone lay awake at night whenever this data science product won’t reach a production stage? If the answer to this question is “No”, it helps to manage any expectations, because chances are the project won’t reach production any time soon.
When you’re interested in something, you do it only when it’s convenient. When you’re committed to something, you accept no excuses; only results. — Kenneth Blanchard
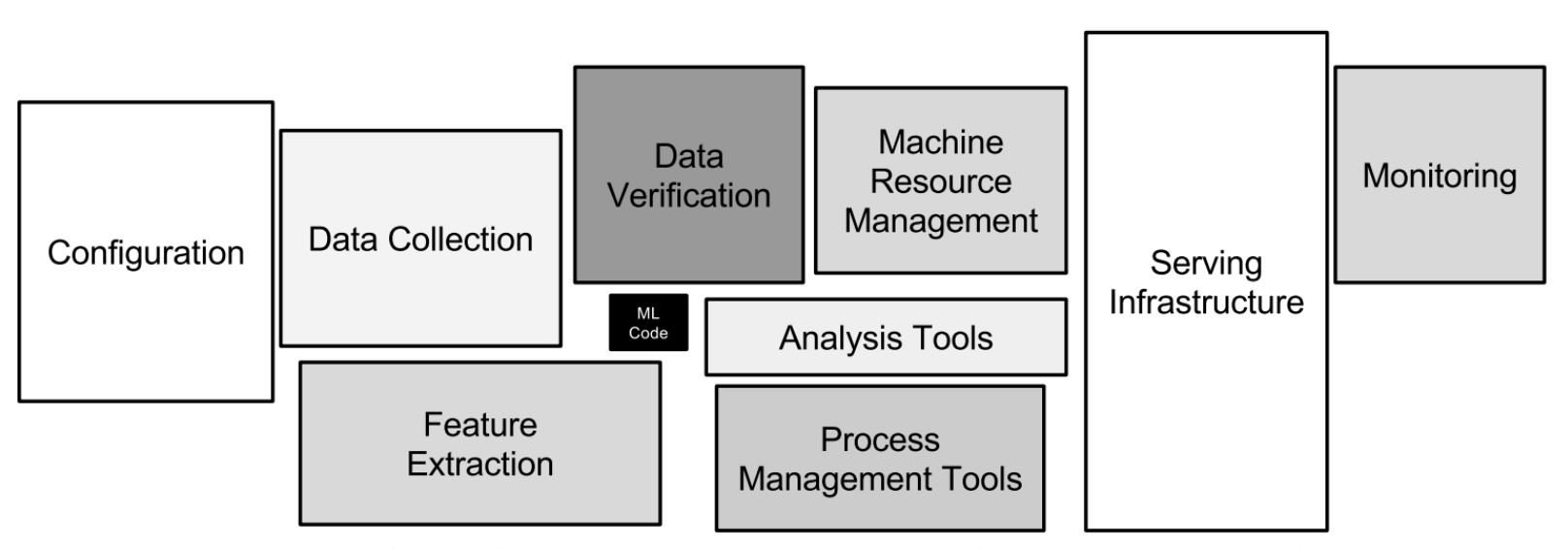
A common understanding of the machine learning pipeline is: you collect data, you gather valuable insights, you train a fancy model and start doing inference for newly arriving data. Undoubtedly, these steps are part of the pipeline, but it is only the tip of the iceberg. The required infrastructure to build, run and manage production level machine learning systems is vast and complex, as illustrated in the diagram above. Note the actual size of the black “ML Code” box.
While working as a data engineer for a large Dutch grocery company, I was part of a large data science department with over 25 FTE data scientists and engineers working on a variety of projects. The company was quite advanced in terms of technology, quality data was accessible and the developed machine learning models showed good results. Still, none of the products were running in production. To me, this was mainly because the sheer amount of engineering required to get these models in production was overlooked and underestimated. This hunch was confirmed when they opened multiple vacancies for senior data engineers and machine learning engineers.
To illustrate some of the complexity involved with deploying Machine Learning models, think about the following questions.
In other words, in order to generate business value with data science, not just the science need to happen, but mainly a lot of engineering has to be done. Not building the model pipeline, but building machine learning infrastructure is in my opinion the biggest challenge when it comes to getting data science products in production.
Sure, your first proof of concept project may fail, but when you are committed in building successful machine learning products, you need to start building the required machine learning infrastructure as soon a possible. The risk of not doing so is to end up in the land of nothingness: your PoC was successful, but reaching a production setting is months away. Any momentum that you may have might disappear and chances of reaching production are getting slimmer and slimmer. To prevent this from happening make sure to hire data and machine learning engineers early in the process and start building.
Lastly, when working on the PoC project, think ahead! There are many steps you can take that might increase the complexity of the PoC in the short run, but will greatly reduce the complexity of going to production later. For example: rather than writing long code blocks, write your code into small testable functions including doc strings or leverage standard logging libraries for debugging your code.

For most data science projects having a successful proof of concept and a value delivering product are two worlds apart. In this blog, I have highlighted some of my learnings and explained what aspects are most important for closing the gap between proof of concept projects and successful data science products. I would say, these are the main take-aways:
I hope you can put my learnings to good use! Disregard them and you might just end up with expensive math 😉.