Common hyperparameter tuning techniques such as GridSearch and Random Search roam the full space of available parameter values in an isolated way without paying attention to past results. Tuning by means of these techniques can become a time-consuming challenge especially with large parameters spaces. The search space grows exponentially with the number of parameters tuned, whilst for each hyperparameter combination a model has to be trained, predictions have to be generated on the validation data, and the validation metric has to be calculated.
Hyperparameter tuning by means of Bayesian reasoning, or Bayesian Optimisation, can bring down the time spent to get to the optimal set of parameters — and bring better generalisation performance on the test set. It does this by taking into account information on the hyperparameter combinations it has seen thus far when choosing the hyperparameter set to evaluate next.
Hyperopt is a Python library that enables you to tune hyperparameters by means of this technique and harvest these potential efficiency gains
In this post, I will walk you through:
All the code in this post can be found in the Hyperopt repo on my GitHub page.
Grid search is the go-to standard for tuning hyperparameters. For every set of parameters a model is trained and evaluated after which the combination with the best results is put forward. In small parameter spaces grid search can turn out to be quite effective, but in case of a large number of parameters you might end up watching your screen for quite some time as the number of parameter combinations exponentially grows with the number of parameters.
A popular alternative to grid search is random search.Random search samples random parameters combinations from a statistical distribution provided by the user. This approach is based on the assumption that in most cases, hyperparameters are not uniformly important. In practice random search is often more efficient than grid search, but it might fail to spot important points in the search space.
Both approaches tune in an isolated way disregarding past evaluations of hyperparameter combinations. They further stick to the full domain of parameters available — which might lead them to evaluate unpromising areas of the of the search space.
Bayesian optimisation in turn takes into account past evaluations when choosing the hyperparameter set to evaluate next. By choosing its parameter combinations in an informed way, it enables itself to focus on those areas of the parameter space that it believes will bring the most promising validation scores. This approach typically requires less iterations to get to the optimal set of hyperparameter values. Most notably because it disregards those areas of the parameter space that it believes won’t bring anything to the table.
This in turn limits the number of times a model needs to be trained for validation as solely those settings that are expected to generate a higher validation score are passed through for evaluation.
So how does it work? There are three main ingredients to it:
Before digging into the specifics of these three components and comparing Bayesian Optimisation to GridSearch and Random Search, let us generate a dataset by means of Scikit-learn’s make_classification method. For this purpose we generate a random binary classification dataset with 1000 samples and 100 features and split it in a train and test set:
In order to compare three previously mentioned hyperparameter tuning methods, let us also define a function that runs either a GridSearch or a Random Search as defined by a user. It takes in a Scikit-learn pipeline (containing our classifier), a parameter grid, our train and test set, and the number of iterations in case of a Random Search. In turn, it returns the optimal parameters, its corresponding cross-validation score, the score on the test set, the time it took and the number of parameter combinations evaluated.
For the purpose of our comparison, we further opt for a gradient boosting model as it comes with a vast suite of parameters, which for a parameters optimisation exercise like this will be of great use.
Last but not least, we define our GridSearch and Random Search parameter grid below. In case of a GridSearch, there are 1,458 parameters combinations it will iterate over. Random Search, on the other hand, will randomly sample from the predefined ranges below (which match up with the GridSearch parameter ranges).
Having constructed our train and test sets, our GridSearch / Random Search function and defined our Pipeline, we can now go back and have a closer look at the three core components of Bayesian Optimisation, being 1) the search space to sample from, 2) the objective function and 3) the surrogate- and selection functions.
1) Choosing the search space
Bayesian Optimisation operates along probability distributions for each parameter that it will sample from. These distributions have to be set by a user. Specifying the distribution for each parameter is one of the subjective parts in the process. One approach to go about this is to start wide and let the optimisation algorithm do the heavy lifting. One could then in a subsequent run opt to focus on specific areas around the optimal parameters retrieved from the previous run.
Parameter domains can be defined along a number of Hyperopt-specific distribution functions. In order to provide a level playing field, let us work along the same minima and maxima we are using in the GridSearch and Random Search parameter domains we previously defined. When it comes to the learning rate, we opt for a continuous log uniform distribution (evenly distributing float values on a logarithmic scale). We do this as we ideally want to tap onto values such 0.01, 0.1 and 1, instead of a regular evenly distributed set of say 0.1, 0.2, 0.3,…,1. hp.loguniform enables us to set up the learning rate distribution accordingly. The hyperparameters max_depth, n_estimators and num_leaves require integers as input. In addition to this requirement, and like the learning rate, we have to make an assumption about their distributions. Generally, it is equitable to assume for these parameters that each value in the specified range has an equal probability. Discrete uniform probability distributions like this can be put in place with hp.quniform in combination with scope.int. The type of gradient boosting technique consists of a list of categories. Parameters in this particular area can be represented by means of hp.choice. Last but not least, we have our regularisation parameter lambda and colsample_bytree, which both require floats. Again, we assume the values of these parameters are equally likely. hp.uniform enables us to employ uniform continuous distributions.
2) Objective function
The objective function (1) serves as the main evaluator of hyperparameter combinations. It simply takes in a set of hyperparameters and outputs a score that indicates how well a set of hyperparameters performs on the validation set. For our classification problem we will use the ‘accuracy’ score as the evaluation metric of choice. In this case, clearly the aim is to maximise the objective function. However, evaluating each set of hyperparameters by means of the objective function can become quite a costly operation when dealing with large hyperparameter grids as we each time need to train a model in order to put it forward for evaluation on the validation set. Hence, calling this evaluation should ideally be restricted to a minimum.
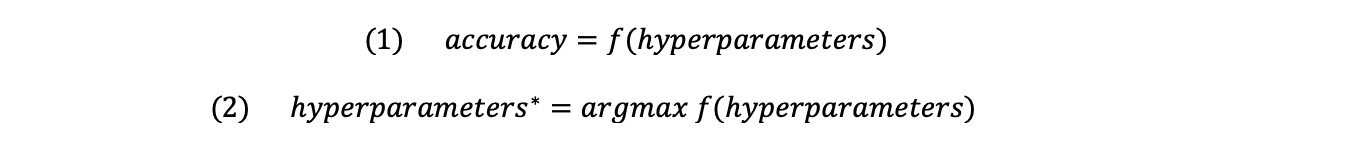 (1) the objective function and (2) the optimal set of parameters that maximise the accuracy score
(1) the objective function and (2) the optimal set of parameters that maximise the accuracy score
In a Hyperopt setting, the objective function in its simplest way can be defined as follows:
It takes in a set of hyperparameters, trains a classifier and returns a cross validation score. Note that our function returns a negative score, this as the Hyperopt optimiser requires a value to minimise. Maximising accuracy scores is equal to minimising negative accuracy scores. This score is passed on to the optimiser, which we’ll deal with in a second. The status key returns the parameters evaluated.
3) Surrogate function and selection function
Ideally, we only want to fire the objective function once we are reasonably sure that we have a set of parameters that leads to a decrease in the validation score. Why not construct some kind of a lightweight assistant that tracks parameter sets evaluated thus far and uses this to advise us on the parameters to put forward to the objective function?
This is where the (3) surrogate- and the (4) selection function come in. Both work together to propose those parameters of which it believes will bring the highest accuracy on the objective function.
The surrogate function can be interpreted as an approximation of the objective function. It is used to propose parameter sets to the objective function that likely yield an improvement in terms of accuracy score.
There are different algorithms for the surrogate of the objective function. Hyperopt uses something called the Tree Parzen Estimator (TPE). Alternatively approaches for the surrogate are the use of Gaussian Processes (through GPyOpt) or a Random Forest Regression (by means of SMAC).
In the case of TPE, the surrogate function is a probabilistic model that maps hyperparameters to a probability of a score on the objective function. In short, it is an application of Bayes’ Theorem (4). A prior distribution is updated to a posterior distribution every time more data becomes available. The data in this case is the score we get back from the objective function on the parameter we have asked it to evaluate. With each iteration it becomes a more accurate predictor of validation scores.
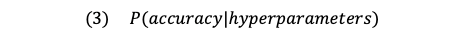
The surrogate function 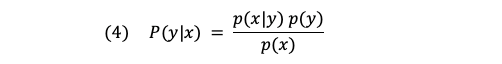
Good old Bayes’ Theorem
The probability of a set of hyperparameters given an accuracy score , p(x|y), has a bit of a twist to it when it comes to TPE. This probability is broken into two separate distributions, being l(x) and g(x). The former defines the distribution of hyperparameters when the (negative) accuracy score is lower than a score threshold, y* (e.g. the top accuracy score achieved thus far). The latter represents the hyper parameter distribution for scores above this same threshold.
l(x) and g(x) each are a Gaussian mixture, or a linear combination of Gaussians. Each time a hyperparameter set is evaluated by the objective function it gets a corresponding Gaussian within mixture l(x) or g(x) depending on the validation score it got back. The mean of this corresponding Gaussian is the point sampled from the prior distribution. Its standard deviation is the greater of the distance to its immediate neighbour on either side. Each mixture is updated after each iteration after which it is used to sample the next hyperparameter combination that maximises Expected Improvement.
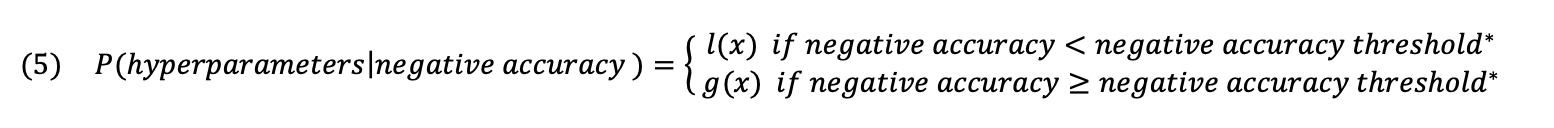
The probability of a set of hyperparameters given an accuracy score broken down into two distributions
In Bayesian Optimisation the hyperparameters that are put forward for evaluation by the objective function are selected by applying a criterion to the surrogate function. This criterion is defined by a selection function. A common approach is to use a metric called Expected Improvement. For a TPE-based surrogate function, the Expected Improvement is given by the following equation:
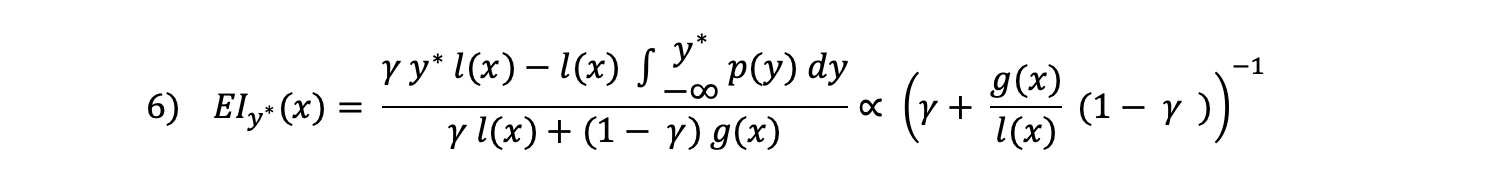
Getting to the hyperparameter set that maximises Expected Improvement
One of the main take-aways of this equation is that one should maximise the ratio l(x) / g(x) in order to maximise the Expected Improvement. To maximise this ratio, hyperparameters values which are more likely under l(x) than under g(x) should be drawn. In other words, you want a high probability of a set of hyperparameters given a negative accuracy score below the threshold y*. This is exactly what TPE does. It samples hyperparameters from l(x), screens them in terms of the ratio l(x) / g(x), and puts forward the set that corresponds to the largest expected improvement.
The threshold y* is defined by the variable γ, which represents the quantile of of the negative accuracy scores (observed thus far) to use as cut-off point. This threshold is set at 15% by default.
The other take-away of the Expected Improvement equation is its ability to trade-off exploitation and exploration. High values of Expected Improvement correspond to points where the surrogate function predicts a high accuracy, whilst they also relate to points where the prediction uncertainty is high. However, the hyperparameter set that maximises Expected Improvement is no guarantee for improved performance versus the best hyperparameter set thus far — predominantly as we’re dealing with hyperparameter probability distributions that are driving Expected Improvement instead of fixed values.
The optimisation process
So how do all these ingredients come together? After setting the initial parameter distributions and putting the process in action Bayesian Optimisation works as follows:
For each iteration:
The surrogate function initially starts off as a weak approximation of the objective function as its probability distributions for l(x) and g(x) are widely defined (i.e. they resemble our initial parameter distributions). However, at each step the feedback retrieved from the objective function is used to update these distributions by means of Bayesian reasoning. Each time l(x) and g(x) become a more accurate reflection of the actual distribution of sets below and above the threshold, *y — and thus a better predictor of validation scores given a hyperparameter set. At each step a new hyperparameter set is chosen that maximises Expected Improvement. This selection is made based on the updated distributions l(x) and g(x).
Setting up the optimisation in Hyperopt
The most complex part of Bayesian Optimisation, setting up the surrogate- and selection function and kicking off the algorithm in Hyperopt, can be done in one single line by using Hyperopt’s fmin function. To use the Tree Parzen Estimator for the surrogate function, simply import tpe. In addition, you put in your objective function, parameter grid and the number of iterations and off you go.
In order to see what is going on under the hood, we add one additional argument, being the Trials function. This function stores basic training information and the dictionary returned from the objective function (being the scores and their corresponding parameters).
Hyperopt taking on GridSearch and Random Search
Let’s break it down and see how Hyperopt compares to GridSearch and Random Search on our dummy dataset. For the sake of ease, we have wrapped our objective function and optimiser in one function, as shown below.
Let us run GridSearch, Random Search and our Hyperopt function on the parameter grids defined above. The latter two require the number of iterations to be specified, which we will set at 75 for both so that we have a level playing field.
GridSearch takes on all 1,451 parameter combinations and does this in about 4 minutes with an accuracy score on the test set of 79%. As expected, Random Search and GridSearch are notably faster as they solely have to evaluate 75 hyperparameter combinations. Hyperopt ends up a bit slower than Random Search, but note the significantly lower number of iterations it took to get to the optimum. Also, it manages to get to a relatively better score on the test set. This is why you would want to use Hyperopt. However, do keep in mind that Hyperopt not always ends up on top. Random Search could bump into the optimal set right at the start just by luck.

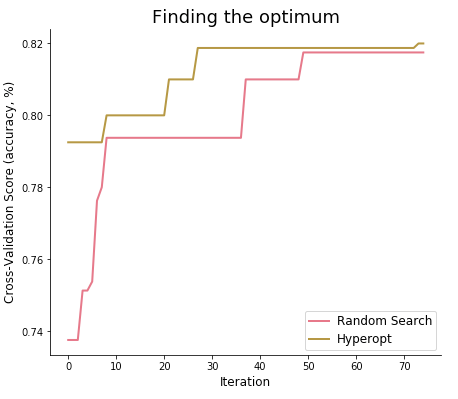
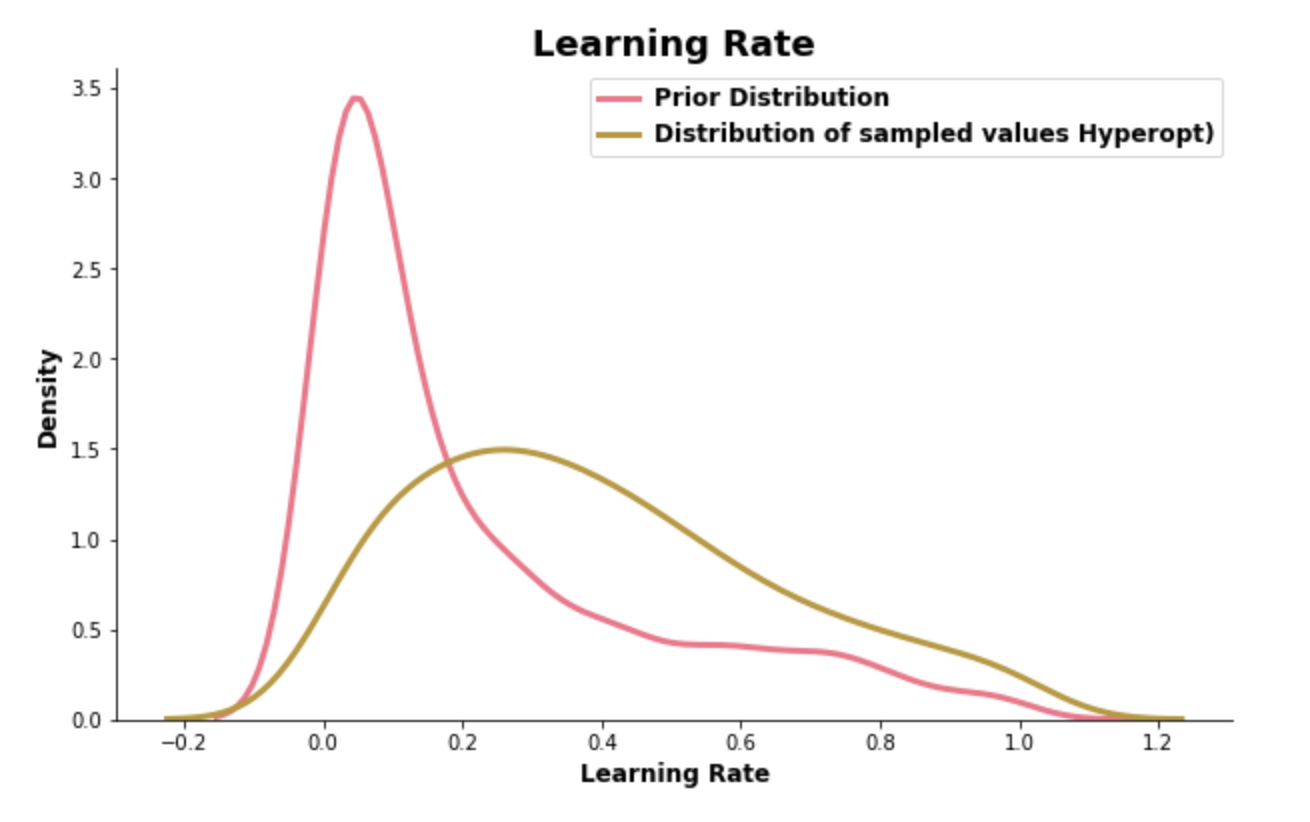
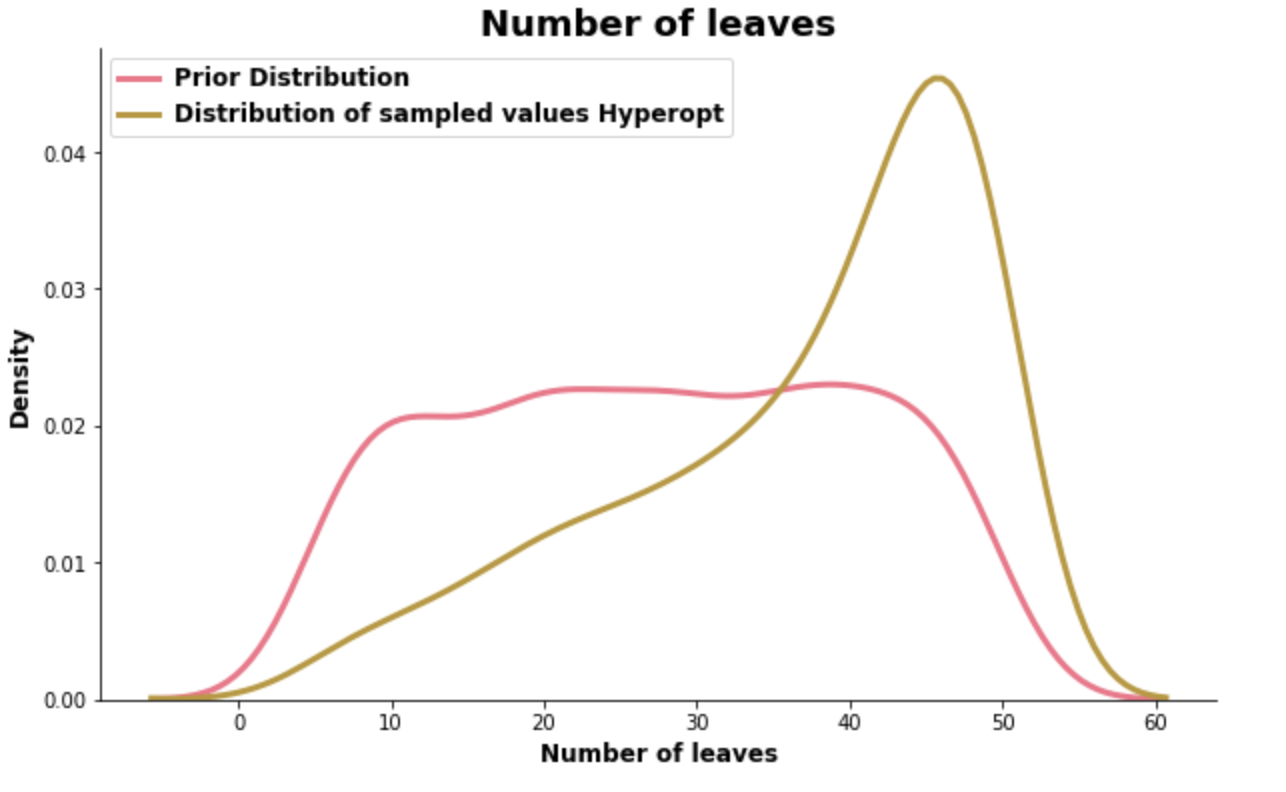
As it evaluates hyperparameter combination by hyperparameter combination put forward by the surrogate- and selection function, it gradually focuses more and more on a specific area of each hyperparameter distribution. Based on past evaluations, it believes that this is where it should be able to find better cross-validations scores. The distribution plots of the learning rate and the number of leaves shown below clearly echo this approach.
Conclusion