

After creating your model and determining you've outperformed your baseline, you want to put your model to the test in a real-life context and make it accessible for other components in your infrastructure. This chapter describes several options on how to do this and what you should consider when choosing the best option for your use case.
8.1 What is model serving?
Model serving is the process of making your created ML model accessible to outside requests, so it can actually be applied and solve the use case.
Let's take a webshop recommendation engine model as an example. A machine learning engineer will first develop a model locally that is able to recommend new products to customers based on previous products that the customer has shown an interest in. They will evaluate the model with evaluation metrics such as precision, recall and AUC. Next, the model should be connected to actual webshop data streams, such as which products a customer has bought or clicked on, which are transformed into the feature set the model expects. The model will then return the prediction or recommendation that will be shown to the user. To connect these data streams we will have to serve out a model, such that there is an endpoint to connect the data streams to. For this generally a few things are needed: a hosting environment that can be accessed through the web, an API that is running on this hosted environment, and the actual model that will serve out the recommendations. The next paragraphs cover which tools and services we can consider to set up these requirements.
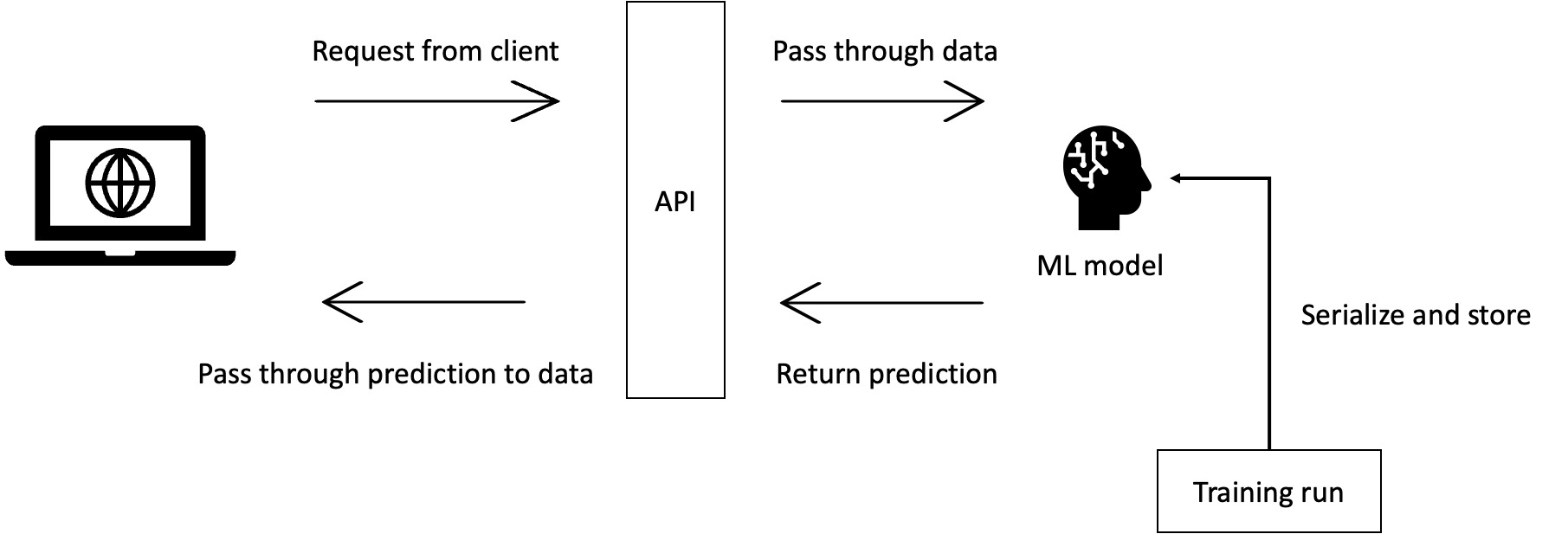
8.2 Choosing an architectural setup, tool and level of abstraction.
When developing a model serving setup, there are a number of tools and levels of abstraction that can be considered. The higher you go in abstraction, the more the tool will do for you, but the less flexibility you will have in changing the internal functionalities. Whereas the lower you go, the more control you will have over the details, while having less built-in functionalities.

An important thing to consider is how and where to host the model serving API and/or model itself. Cloud hosting makes it possible for your API and model to be accessible for other applications and services. Cloud hosting however comes with a price (literally), which should be considered when determining the best setup for your context.
Scalability is another import aspect to keep in mind when thinking of the architecture. It is relatively easy to create a quick API model serving solution that will work for one user, but as your userbase grows, the load on your application will as well. So, when developing your application making sure it can handle the required load is necessary for it to be production ready. For an in-dept guide on how to make your ML model scalable this blog is a great resource.
8.3 Examples
In this section we will consider two example setups to serve your machine learning model:
- FastAPI + internal model
- MLFlow Serving + cloud stored model
FastAPI + internal model:
In this method a REST API is created for the handling of outside requests using the FastAPI library. You can think of a REST API as a mediator between the client (front-end) of an application, and the resources or logic (back-end) of the application. This mediator uses a set of definitions and protocols that can be used in combination with a wide range of client applications and programming languages.
A REST API will receive requests from a client such as a website, app or other application, and pass it along to the back-end logic, such as getting predictions from a machine learning model. In that case the REST API contains a trained and serialized model, so it can be used whenever requests are sent to the API.
This method has the advantage that it's light-weight and performs only the request handling, making this method flexible in terms of model loading and inference methods. It has however the disadvantage that it does not have specific model deployment features, requiring the developer to build these from scratch or import them from other libraries. This means the developer will, for example, need to write functionalities to import the trained model artifact, as well as write custom inference code that is compatible with the model that was trained. Changing to a new model version will also need to be either manually performed or require custom code to be added.
More on this method in this Vantage blog.
MLFlow Serving + cloud stored model
In this method we go up in abstraction compared to having a model stored in a FastAPI. We will consider a solution including a tool called MLFlow, which can monitor, store, and serve models within its framework. When using MLFlow for serving, a best practice is to use cloud based storage (e.g. AWS S3 or Azure Blob storage) as a model storage location. This makes it possible for MLFlow to access, version and serve models easily.
When training a model, the results of the model training run can be stored and observed within a MLFlow interface. In addition to this, the model artifact (pkl file) will be stored alongside these experiments to make it easy to deploy after determining this model is the best performing one.
In addition to the experiment tracking, MLFlow has a built-in serving framework that spins up a REST API service, takes in requests and passes these to the model to produce and return predictions. The model that is currently in production can easily be replaced within MLFlow by changing the label assigned to the model (e.g from Development to Production), which will promote the new selected model as the one to be deployed. Since the experiments are stored alongside the model artefacts, MLFlow makes it easy to determine which model performed the best, so this one can be labeled for deployment to production.
This method has the advantage that it has many supporting features that are specific to ML model experiment tracking and serving. It has, however, the disadvantage that is less flexible, and changes in the supporting features are not easily made. You can read more about this method in this Medium post.
Finally, it is worth pointing out that there are a wide variety of tools available for model serving, all of which come with their own pros and cons. Some are specific for a framework (e.g. Tensorflow Serving, TorchServe) and others are framework-agnostic (e.g. BentoML, ClearML). Different tools might work better in a different context, there is no solution that is always right. However, the two solutions described above can be applied in a wide variety of use cases.
8.3 Considerations
Asides from the points mentioned in the previous sections, there are other important aspects to take into considerations when determining the best solution to serve your model to the world. In this section some considerations are described.
Features during training vs inference time
When creating a model serving API it's important to consider the added complexity a ML model has compared to an API that, for example, just queries a database. A ML model is trained on a set of features, which means the model serving API will always need to get a request with those exact features, or the model won't be able to produce results.
This can be an issue when versions of ML models are updated or downgraded. If the next version of the model is trained on a different set of features, the request that comes in through the API (or the transformation logic after the API) will also need to be changed to contain the new set of features. Because the model training and the inference are decoupled in model serving, this needs to be kept in check as an additional step.
Is the API framework right for my use case?
The APIs discussed thus far perform well in situations where requests are done in a client-server fashion where the server waits for a client to request data from it. These are however not the only use cases which would require an API in combination with a ML model.
Let us consider the case where we want to determine sentiment for tweets containing a specific hashtag, update these whenever a new tweet appears with this hashtag, and show the results live in a dashboard. Since the dashboard is the client in this scenario, we want to update it whenever a new tweet is posted. We don't want the screen to constantly ask for an update from the server like in a REST API, but establish a connection once and lay back and wait for the events to roll in. For these event-based use cases a streaming API/processing framework like Kafka would be more fitting.
Furthermore, most machine learning frameworks have optimizations for processing multiple messages (batches) at the same time. A regular API application flow however will get requests from the client and process them one by one. Some frameworks, such as BentoML, take advantage of this efficient batch processing by grouping incoming requests into batches before passing it to the ML model. A batching window can be set which tells the framework how long it should wait before passing the batch to the rest of the application. As you can imagine this can cause some additional latency, but depending on how much faster the ML model processes the batch instead of single requests this can lead to a net positive in processing time.
Model monitoring
While model deployment has a lot of similarities with traditional software deployment, it also has some distinct differences.
One of these differences is the fact models can 'silently' fail, which means they do not give an error when they fail such as in traditional software deployment, but will give out predictions that are not as good as we expected during model development/evaluation. This can happen both directly after deploying the model to production, for example due to incorrect data cleaning and/or feature creation during inference. Alternatively, it can happen over time if the distribution of the data from the real channels drifts away from the distribution of the data we trained on. For both cases of failure the only way to detect them is by monitoring the performance of the model. This monitoring can be done by periodically evaluating the model, storing the metrics and visualising them in a dashboard or alert the ML Engineer by sending an e-mail or Slack message whenever a certain model metric drops beneath a threshold.
More info on model monitoring can be found here.
Assignment
Follow these steps to set up a local model serving API:
- Make sure the model you created in the previous chapters is serialized (in for example a pkl format) and accessible locally.
- Create a REST API using the FastAPI library
- Install FastAPI and an ASGI server using
pip install fastapiandpip install uvicorn[standard]. - Create an inference.py file with a predict function that:
- Loads in the serialized pickle model
- Checks if the incoming data has the expected schema
- Feeds the incoming data to the model and performs a prediction
- Returns the prediction
- Create a main.py where you initialize FastAPI and create one POST API method that can:
- Receive a request and log the body as output
- Call the predict function in the inference.py and pass along the data
- Return the prediction that comes back from the predict function
- Run the main.py method using
uvicorn main:app --reload
- Install FastAPI and an ASGI server using
- Use the Postman desktop tool to send out a request to the local API you created and check if the prediction is correctly returned within the response.