

This blog is the last in a series of three in which we present a case study of a machine learning project we did: predicting house prices. In our previous blogs you can read how you find a valuable machine learning use case (link), and how you can help customers by showing the uncertainty of your machine learning predictions (link). In this final blog we will explain how you can put the machine learning model in production and thereby create value. We will talk about the basic ingredients, which allow you to start small and move to production fast.
A recent article states that 87% of all data science projects are never put into production. Partially this is caused by the experimental nature of data science projects. This is why it is so important to look for use cases that create real value for the end user. In our project this was the case, we can really help the end users with the improved predictions. Now it is time to integrate the model in the business process so it is accessible for the end user. There are different things we need to think about which we will explore in this post. All solutions proposed are open source products and free to use.
When you are at a customer you never know what kind of infrastructure they might have. They can run their services on-premise, or in a public cloud. Independent of this you will need to deliver a solution. One way is to place your code in a Docker container which allows you to run your code on almost any platform. Write a small wrapper around your code that allows it to be requested by other services and you have created a REST API for your model. In this blogpost we show you how to do that if you are working in Python.
There is a broad variety of tools that can be used for this, but usually this is an afterthought. When this is not in place, weird outcomes can go unnoticed, for example when you ask for predictions that are not within the same distribution as the data you trained on. By monitoring your predictions you have a tool to detect mistakes and make changes to your code so they will not happen again.
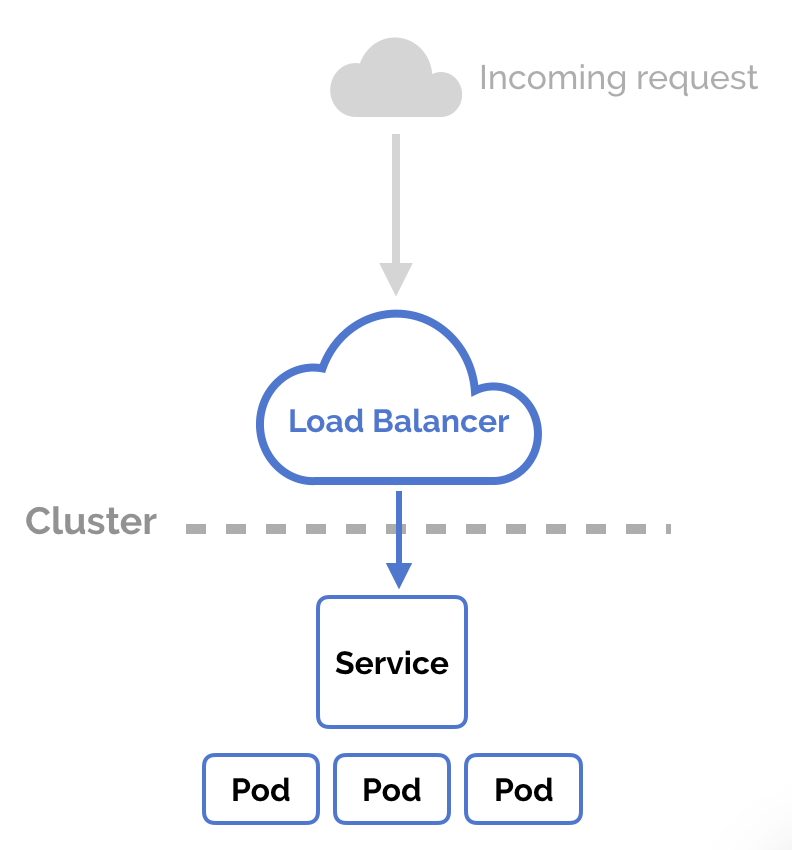
Having a REST API can be sufficient to get started. When needed you can request a prediction which is computed at that moment. However, if you request too many predictions, long waiting times or timeouts will occur. One solution can be to do batch processing: you already make predictions some time ahead and store them for later use. But if you want to have real time predictions there exists another solution. Instead of having a single Docker container that can give you predictions, you can add a second or third one, thereby increasing the maximum throughput. This can be easily done by using Kubernetes. Kubernetes is an open-source system for automating deployment, scaling, and management of containerized applications. In addition, if you add a load balancer in front of your Kubernetes cluster it can redirect to the image with the least amount of load. A load balancer is a built-in function of Kubernetes. Combining this with an auto scaler will ensure that there will always be enough computing power available as it will add new Docker containers when the load is too high across the already existing containers.
With your model now up and running in a production setting there is one more thing to account for. In some cases, such as the housing market, new data is generated over time which might warrant retraining of your model. By retraining your model with the newest data you can combat model degradation or simply ensure high performance by accounting for time-dependent changes such as fluctuating house prices. Although this could be done manually every week or month, there are also tools to automate this. One way of doing this is by using Airflow, which is a workflow management system originally developed by Airbnb. With this tool you can write a script that will run periodically to retrain your model automatically with the most recent data. The new model performance can be evaluated on a separate test set and compared to the performance of the previous version. If the new model is outperforming previous versions, it can be deployed to production automatically.
In this series of blogs we used a real use case to first show you how machine learning can help to improve your product, next why uncertainty should be accounted for and how this can be done, and finally how your finished product can be put into production. In certain scenarios this process can be more complex than described in this post, but in less complex processes it will be a good start. If you have any questions about any of these posts do not hesitate to reach out to us.


