With datasets ever increasing in size, the optimal use of Pandas is becoming more and more tricky. In this blog I will share four strategies how to deal with large datasets when using Pandas.
Every data scientist knows that data pre-processing and feature engineering is paramount for a successful data science project. Often, however, these steps are time-consuming and involve you waiting for computations to finish, keeping you from creating that awesome model. In this post we will look at a few tricks that intend to speed up your pandas data-crunching workflows by enabling Pandas to use your machine in an optimal way.
Pandas is a powerful, versatile and easy-to-use Python library for manipulating data structures. For many data scientists like me, it has become the go-to tool when it comes to exploring and pre-processing data, as well as for engineering the best predictive features. Even though Pandas is still rapidly improving, we see Pandas users reverting to alternative tools like Spark as datasets become too large to fit in RAM memory. It is unfortunate that you have to learn and use a different tool, only because you have too much data. Therefore, I looked into four strategies to handle those too large datasets, all without leaving the comfort of Pandas:
The most simple option is sampling your dataset. This approach can be especially powerful during the exploration phase: how does the data look like? What features can I create? In other words, what works and what does not. Often a random sample of 10% of such a large dataset will already contain a lot of information. That raises the first question, do you actually need to process your entire dataset to train an adequate model?
If you do need to process all data, you can choose to split the data into a number of chunks (which in itself do fit in memory) and perform your data cleaning and feature engineering on each individual chunk. Moreover, depending on the type of model you want to use, you have two options:
When loading data from file, Pandas automatically infers the datatypes. Very convenient of course, however, often these datatypes are not optimal and take up more memory than needed. We will go over the three most common datatypes used by Pandas — int, float and object — and show how to decrease their memory imprint while looking at an example.
As a default, Pandas sets the dtype of integers to int64, this datatype takes in 8 bytes and can represent humongous integers, from -9223372036854775808 to 9223372036854775807. Many times, however, integers represent countable entities, like number of cars or visitors per day. Those type of numbers can easily be represented in the four times smaller dtype int16. If your data fits in the range -32768 to 32767 convert them to int16 to achieve a memory reduction of 75%! In case your data is positive and under 65535, go for the unsigned variant, uint16.
In the same way, the float class consists of float16, float32 and float64, where the latter is Pandas’ default. Float64 can represent both very small and large numbers with high precision, which makes it suitable for accurate calculations. Often, however, you find yourself working with already noisy data, like sensor data or data with limited precision from itself such as currency. Again, the smaller datatypes float32 or float16 will serve many use case’s purpose and will reduce your memory imprint with 50%, respectively 75%.
Another way to drastically reduce the size of your Pandas Dataframe is to transform columns of dtype Object to category. Rather than having copies of the same string at many positions in your dataframe, pandas will have a single copy from each string and will use pointers under the hood that refer to these strings. However, notice, that if every row has a different string, this approach will not work.
In the notebook below, I demonstrate a dataframe memory imprint reduction from 88.4%, only by changing the datatypes.
Another way of handling large dataframes, is by exploiting the fact that our machine has more than one core. For this purpose we use Dask, an open-source python project which parallelizes Numpy and Pandas. Under the hood, a Dask Dataframe consists of many Pandas dataframes that are manipulated in parallel. As most of the Pandas API is implemented, Dask has a very similar look and feel, making it easy to use for all who know Pandas.
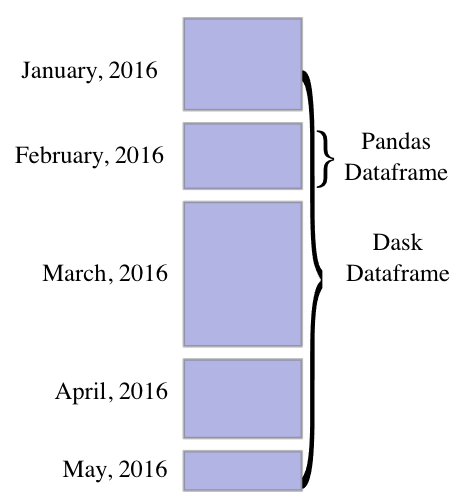
A question that arises is, how can data that does not fit in memory while using Pandas, fit in memory when using Dask. The answer lies in the fact that Dask Dataframes and operations are lazy. This means, operations are not executed immediately, but rather build up a task graph. We can interpret this graph as the recipe for calculating the result. Upon calling the compute method, the build-in Dask task scheduler coordinates partial loading and manipulation of data while making use of all cores. As soon as all intermediary results are computed, Dask combines them and returns the final result.
Without going into anymore detail, consider the example below in which I will do some data processing on the 2015 New York Yellow Taxi dataset. It consists of 12 .csv files of around 2GB each. To have a fair comparison I did the same processing steps also in Pandas. As the full dataset does not fit into memory, my laptop made intensive use of swap space and memory compression in order to make it work.
In the notebook above, we have performed some data manipulation tasks on quite a large dataset using both Pandas and Dask. We can see that the total run time for Pandas amounts to 19 minutes, whereas it only took 10 minutes with Dask, making it almost twice as fast. Moreover, as promised, the syntax and functions used by Dask matches Pandas’ almost 1-on-1, making it essentially trivial to write your Dask workflow if you know your Pandas.
In this post I have shown that not all is lost when your dataset is too large and you insist on using Pandas. Depending on your goal, you can overcome memory issues by applying one of the described strategies. For exploration purposes you are best off by sampling your data. In case you need to process all your data, try iterating over your data or optimising your datatypes. Is your dataset still too large and are you tired of getting coffee every time your calculations are running, then go for Dask to parallelise Pandas.