Fitting and serving your machine learning model is one thing, but what about keeping it in shape over time?
In this blog, we illustrate how you can incrementally incorporate new data in your machine learning model in an automated manner, whilst minimizing the overhead that often comes into play.
Let’s say we got a ML model that has been put in production and is actively serving predictions. Simultaneously, we got new training data that becomes available in a streaming way while users use the model. Incrementally updating the model with new data can improve the model, whilst it also might reduce model drift. However, it often comes with additional overhead. Luckily, there are tools that allow you to automate many parts of this process.
In this post, I am going to walk you through a repository I created that does exactly this. This repo (which can be found here) mainly leans on three nifty tools, being Kafka, Airflow, and MLFlow. Before we dig into the overall setup, let’s briefly touch upon each of these three tools.
Where would these tools fit in when it comes to incorporating new data into your model by means of automated incremental updates? Let’s break it down along the previously mentioned hypothetical case where we have an ML model that is serving predictions:
In order to set up this hypothetical case in a replicable (local) format, whilst simultaneously mimicking the microservices architecture that is nowadays often employed within companies, I have opted to set everything up along a set of Docker containers. A Docker container is an isolated lightweight package that contains one or more applications and its dependencies in a single portable format so that you can quickly and reliably run it from one computing environment to another. The mechanics of Docker containers goes beyond the scope of this blog, but should you wish further background on this matter, then the following link might be of use.
In our case, we need multiple containers with each single one being responsible for taking on one or more bespoke headline tasks. The environment in it simplest form requires five containers — most of which can be put together with the help of prebuilt Docker images :
Schematically, taking into consideration the tasks at hand, this all comes together as follows:
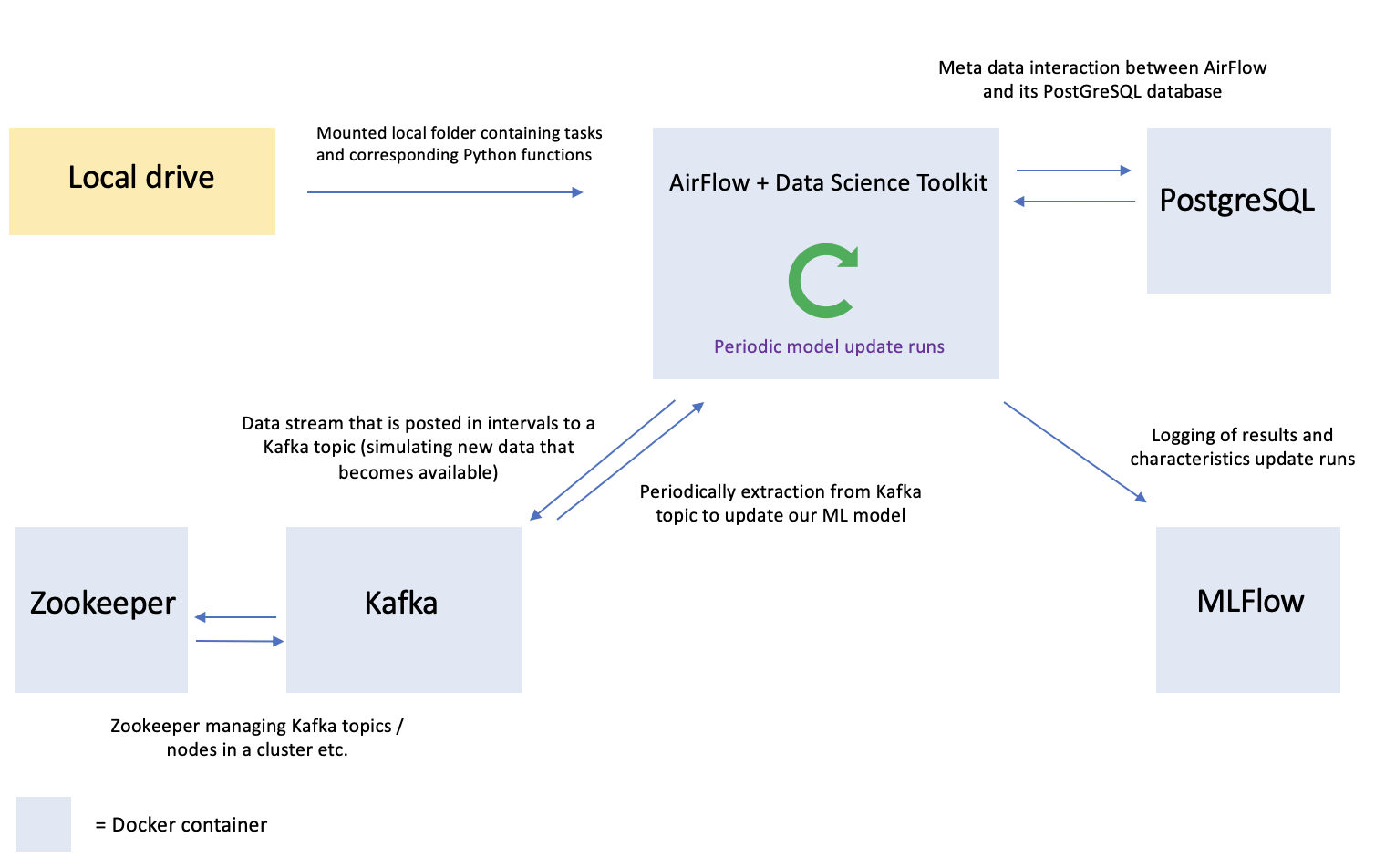
Configuring and setting up five containers separately, whilst also tailoring the communication between containers is rather inefficient. Luckily, there is Docker Compose, which allows you to set up multi-container applications in the blink of an eye.
The Docker Compose YML file in the GitHub repository relating to this blog exactly constructs the above set of containers, whilst also making sure that each container is able to communicate with other containers it requires to communicate with (e.g. Airflow with PostgreSQL, Kafka with Zookeeper etc.).
Project folder structure
Before moving on to train the initial model, let’s define the folder structure of the project. As shown in the scheme below, we start with a ‘dags’ folder which as its name implies contains DAGs (or ‘Directed Acyclic Graphs’ ). A DAG is a collection of tasks that you can instruct Airflow to periodically run. Each task can (amongst others) execute a Python function. In the ‘src’ subfolder you will find the custom Python functions for our project that AirFlow will load and run as stipulated by each DAG.
Next to this, we want to craft a setup where we have streaming data coming in that in turn is efficiently stored and periodically used to update our model. The streaming data coming in is something we can simulate by sampling from a hold-out set of our data. The data folder is going to contain such a streaming sample. Also, it will contain an archive containing the batches of data that have been used thus far to update our model.
Lastly, we got a models folder that is going to contain the current version of the model, and model versions we have had up-and-running in the past, but have been superseded by model updates.
These folders are mounted to the Airflow container for further use.
project_folder
├── dags
│ └── src
│ ├── data
│ ├── models
│ └── preprocessing
├── data
│ ├── to_use_for_training
│ ├── used_for_training
├── models
│ ├── current_model
│ └── archive
├── airflow_docker
├── mlflow_docker
└── docker_compose.yml
Training the initial model
For this occasion we turn to the good-old MNIST handwritten digits database and train a Keras prefab convolutional neural network that classifies pictures of handwritten digits.
Training the initial model is a one-off operation that we can hand over to Airflow for execution. This is where the first DAG comes in. The initial model DAG (initial_model_dag.py) exactly tells AirFlow which Python functions to load and in which sequence to execute them in order to train the first version of our model.
A DAG typically consists of three parts, being 1) a section where you define headline DAG characteristics, such as the interval at which AirFlow ought to run the DAG 2) the individual tasks it ought to run and 3) the order along which the tasks ought to be executed.
The DAG for the initial model basically does the following along two headline tasks:
1 ) Load & preprocess MNIST data. Task 1 downloads the MNIST dataset, splits it in a train, test and streaming set — and puts them in the right format for training the CNN. The idea here is to use the train set for training the initial model, whilst using the test set for gauging the performance of both the initial model and subsequent model updates. The streaming set will be used to simulate data streams of ‘new data’ that are pushed to Kafka. Each set is stored in the data folder.
2) Construct & fit the model. Task 2 amongst others fetches the train and test set from the previous task. It then constructs and fits the CNN and stores it in the current_model folder
This DAG is to be triggered once, which is exactly what the schedule_interval tells Airflow to do. It is furthermore crucial to stipulate how both tasks stack up in terms of relative ordering. In the case of this DAG, task 1 has to run successfully before task 2 can run. This is done by means of the following piece of code:
task1 >> task2Below you will find the initial_model_DAG and its corresponding custom Python functions.
Before kicking off this DAG, let’s structure how we’re going to generate data streams (representing the new data that becomes available) that feed into Kafka and in turn periodically extract data from this feed to update the model.
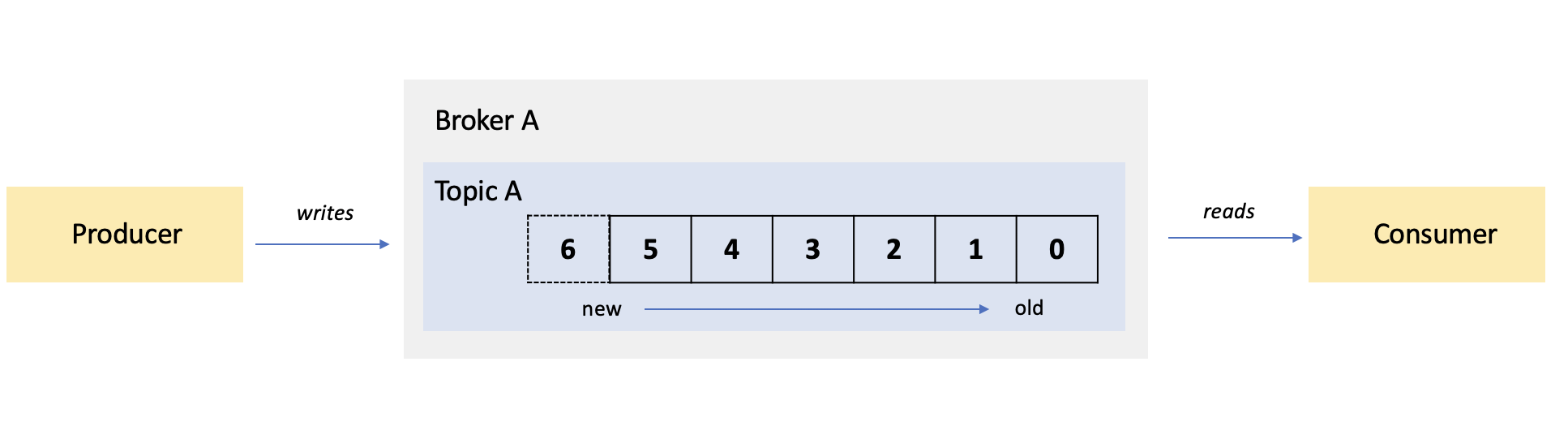
Kafka is one of the go-to platforms when you have to deal with streaming data. Its framework basically consists of three players, being 1) brokers; 2) producers; and 3) consumers.
A broker is an instance of a Kafka server (also known as a Kafka node) that hosts named streams of records, which are called topics. A broker takes in messages from producers and stores them to a topic. It in turn enables consumers to fetch messages from a topic.
In its simplest form, you have one single producer pushing messages to one end of a topic, whilst one single consumer fetches messages from the other end of the topic (like for example an app). In the situation of our case where we have Kafka running locally, a single setup likes this (shown below) does the trick.
However, it doesn’t quite cover the parallelization strengths of Kafka. What if you for example have 100,000 messages coming in per minute from a producer, which in turn ought to be consumed in a swift and efficient fashion? One way to tackle this would be to bring together multiple brokers in a Kafka cluster (let’s say 10) with each broker getting assigned a so-called partition of the topic. Along this way, each unique message would then be appended to a single partition as it comes in. Then, you could assign each partition to a single consumer — with the end-result being 10 consumers processing 10,000 messages in parallel.
As this post focuses on the engineering required to automate the process of incorporating new data in a ML model, we don’t quite require an extensive set of producers, brokers and consumers. Therefore, we stick to one producer, one broker and one consumer. This can be traced back in the Docker Compose YAML file, where in the section that sets out the Kafka container you can find the set up of one topic with one partition and one replica (i.e. a backup copy) along the following instruction: KAFKA_CREATE_TOPICS: "TopicA:1:1" .
With the help of the Kafka-Python API we can now simulate a data stream by constructing a Producer that publishes messages to the topic. In dags/src/data/kafka_producer.py (shown below)you will find a function that 1) sets up a Producer that connects to the topic and 2) randomly samples observations from the streaming sample we previously stored in the data folder, which it in turn converts to JSON and pushes to the Kafka topic.
Now that we have constructed the Producer function, we can create a DAG around it so that Airflow can periodically trigger a stream of data that is pushed by the Producer into the topic. In dags/stream_DAG.py (shown below)you will find exactly the DAG that does this. Let’s park the actual ‘trigger’-part of the DAG for now and move on to the part where we periodically fetch data from the topic, which is then used to update the model.
To fetch the data from the Kafka topic, we turn again to the Kafka-Python API to construct a Consumer. This Consumer is wrapped in a function that sequentially retrieves observations from the topic, which it in turn converts back from JSON to its original format and groups together in a NumPy array which is stored (in pickle format) in the to_use_for_training folder. Next to this, we need a function that loads the data from the to_use_for_training folder, so that it can be incorporated it in the ML model. Both functions can be found in dags/src/data/data_functions.py, which is shown below.
From here we enter the part where we actually get to define how to update the model. In dags/src/models/update_functions.py, you will find the custom Python functions that take care of this (shown below).
The update_model function in update_functions.py does most of the heavy lifting:
*Note: we are working here with a test set that remains static over each update run. In order to properly assess the relative performance of a model , it might be worthwhile to adjust the test set in line with how the real life environment of the model changes . However, as we’re focusing on the engineering side of things in this blog, we will pass on the construction of a dynamic test set.
**Note: As we do more and more update runs over time, the neural network can have the tendency to forget the things it learned from the original (initial) dataset. In case the real life environment changed and the new data resembles this new situation, there is nothing much wrong. However, if this isn’t the case one might choose to blend a small portion of the original dataset in each periodic new data sample, to cover for this tendency.
The only thing that’s remaining on the list, is a DAG that sequentially triggers these functions (and thus updates the model) at an interval of our choice. This DAG can be found in dags/src/update_dag.py — which is shown below.
The main trick here is that we pass on variables as a result of a task to the next task. This is done by so-called XCOMs, which allows tasks to exchange messages. Take for example the preprocessing task in the DAG above. Once we have loaded the data with the preceding load_data task, we then in the next task (the preprocessing task) access this data by calling the output variables of the load_data task. This is done by means of the below:
ti = kwargs['ti']
loaded = ti.xcom_pull(task_ids='load_data')Note that throughout this DAG quite some of the actions involved in incorporating new data in the model are put in separate tasks. This especially from a monitoring point of view can come in handy as this allows you to swiftly pinpoint bottlenecks in the process in case something has gone wrong during an update run.
Now that we have all the DAGs and corresponding functions defined, it is time to get the ball rolling and train an initial model, post streaming data to Kafka, fetch this data and update the model. To do this, we have to start the environment by executing the Docker Compose YML, which is done by running the following commands:
docker compose -f docker-compose-project.yml build
docker compose -f docker-compose-project.yml upWith these commands, you got the five containers up and running. You can check this by opening the Airflow and MLFlow dashboards in your browser through localhost:8080 and localhost:5000, respectively.
Now, to turn on each of these DAGs you have to sequentially nudge each respective switch on the Airflow dashboard (shown below). Once this is done, it will instantly train an initial model, push streaming data into the bespoke Kafka topic and update the model. From that point on, it will post streaming data to the Kafka topic on an hourly basis and update the ML model on a daily basis (at midnight).

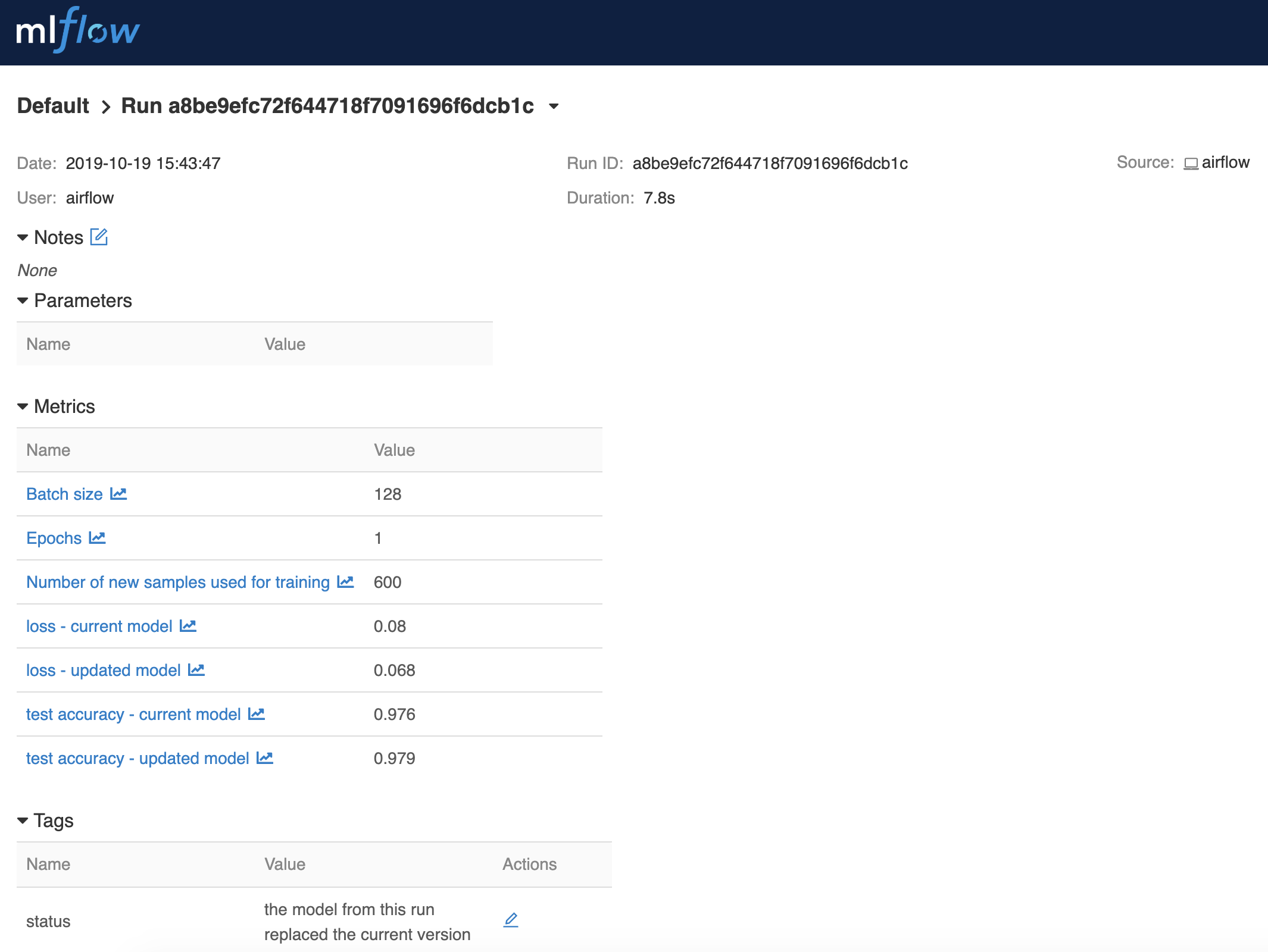
The results of each update run are logged to MLFlow (shown in the figure below). Along its current setup, you will find for each run, the number of samples that were used to update the model, the accuracy and loss of the model that is currently in place and the updated model, the number of epochs and the batch size used — and whether or not a run led to the current version of the model being replaced.
In summary, we train an initial model, we simulate streams of new data that are pushed to a Kafka topic on an hourly basis, and we fetch new data from this same topic every day and use it to update the model. We do this by leveraging the streaming data capabilities of Kafka, the task automation power of Airflow and the logging features of MLFlow — all structured along a set of Docker containers orchestrated by means of Docker Compose.
There are many more things you can do with these tools in a machine learning setting — and there is ample room for further tweaking beyond the basics when it comes to incorporating new data in a ML model. That said, should you have further suggestions for expanding on this topic — do feel free to drop me a line!