Some years ago, I used to think I was a data scientist because I was able to understand and implement ML, I had experience with data in the wild, and I had built prototypes that showed the potential value of data science for the business. As a data scientist, coding was merely the tool to get things done, and, when programming, there are many ways in which things can get done. But, as Adrian Belew says: "It doesn't mean you should just because you can"
In my life as a data scientist, I have come across software development practices that would have made my life much easier if I had known them before. In the hope that I save a lot of time and headaches for my fellow community, here is a collection of them, along with the why's and the when's.
Cookiecutter
What?
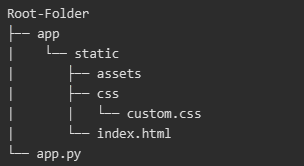
Cookiecutter creates a project from a project template, which spares you the pain of figuring out how to structure the files and folders of your project, as well as providing a skeleton for setting up the enviroment of the project, tests, and other useful features. It is of course customizable in case you want to tune it to your preferences, but if you are a newcomer I would advice to first understand the structure of one of the templates like this one, and the motivations therein. Here you can find some benefits of having a well-structured project
When?
In every project you do.
How?
To start, pick one of the templates, start your project by cloning it, and off you go. Learn once, use always. Eventually if you feel something is missing, configure it to your liking,
More info:
Modern Pandas
What?
All pandas roads lead to Rome, but not all of them are equally readable, writable, adjustable, nor do they provide the same workflow. Modern Pandas provides principles to use pandas, in an attempt to maximize all of the above. Perhaps my favorite principle is method chaining.
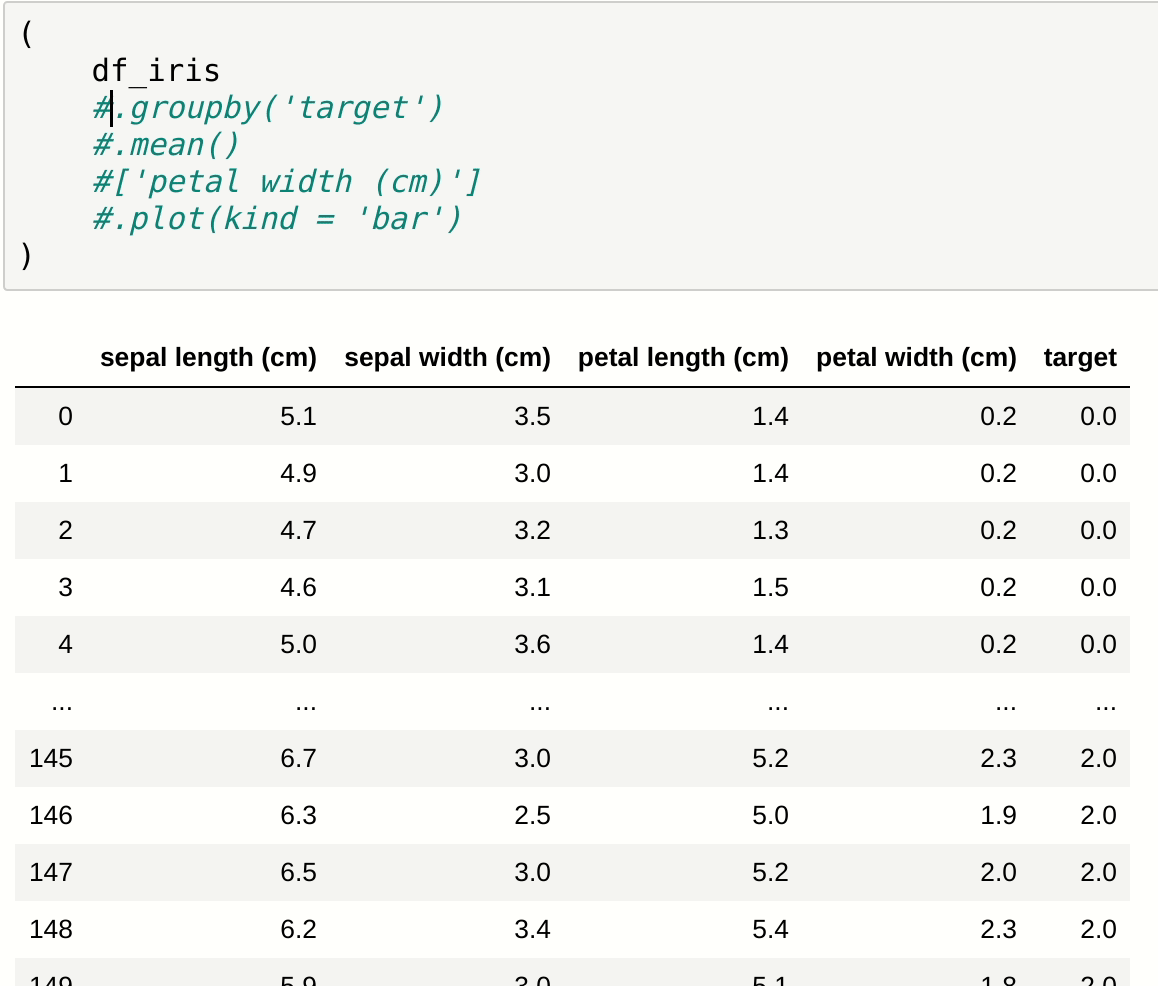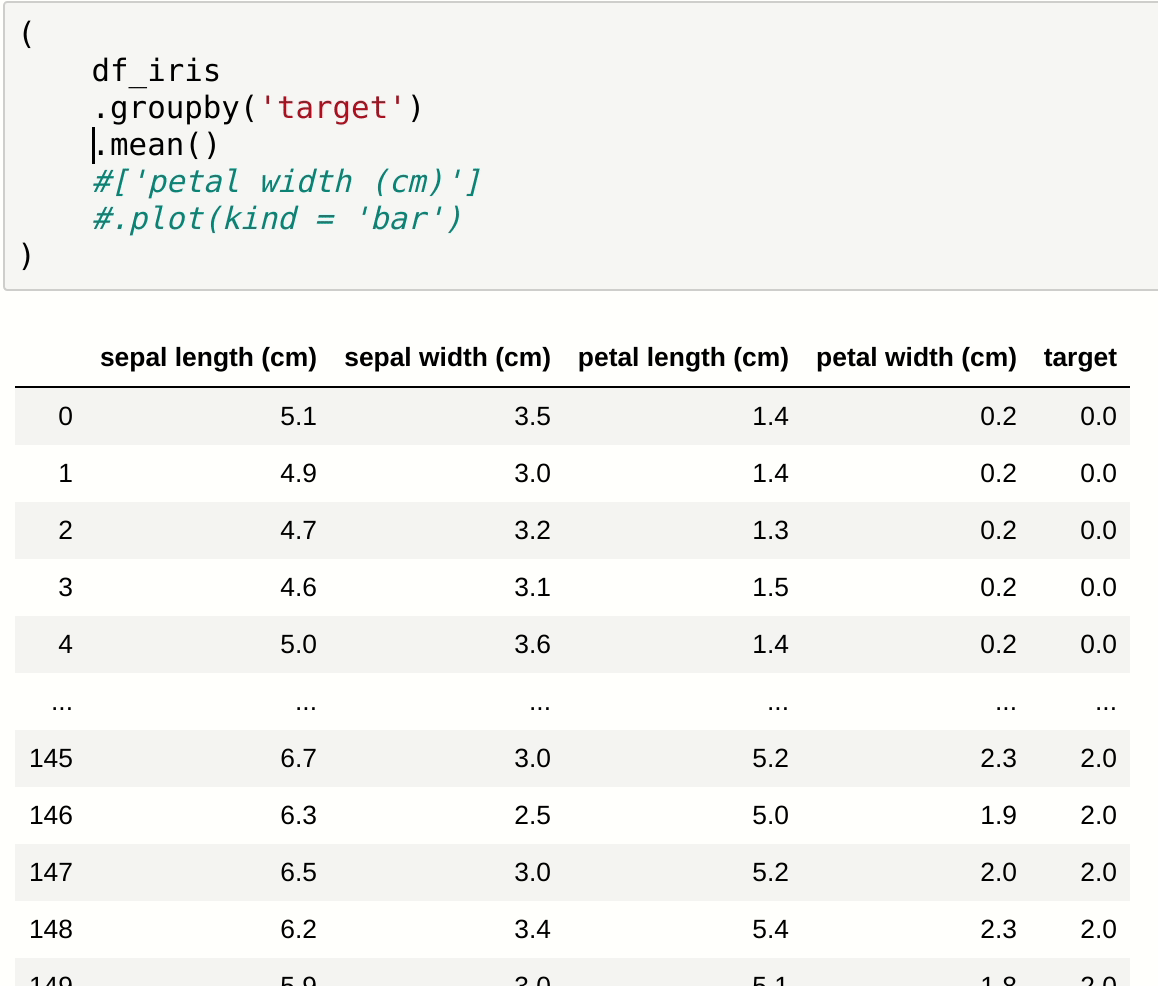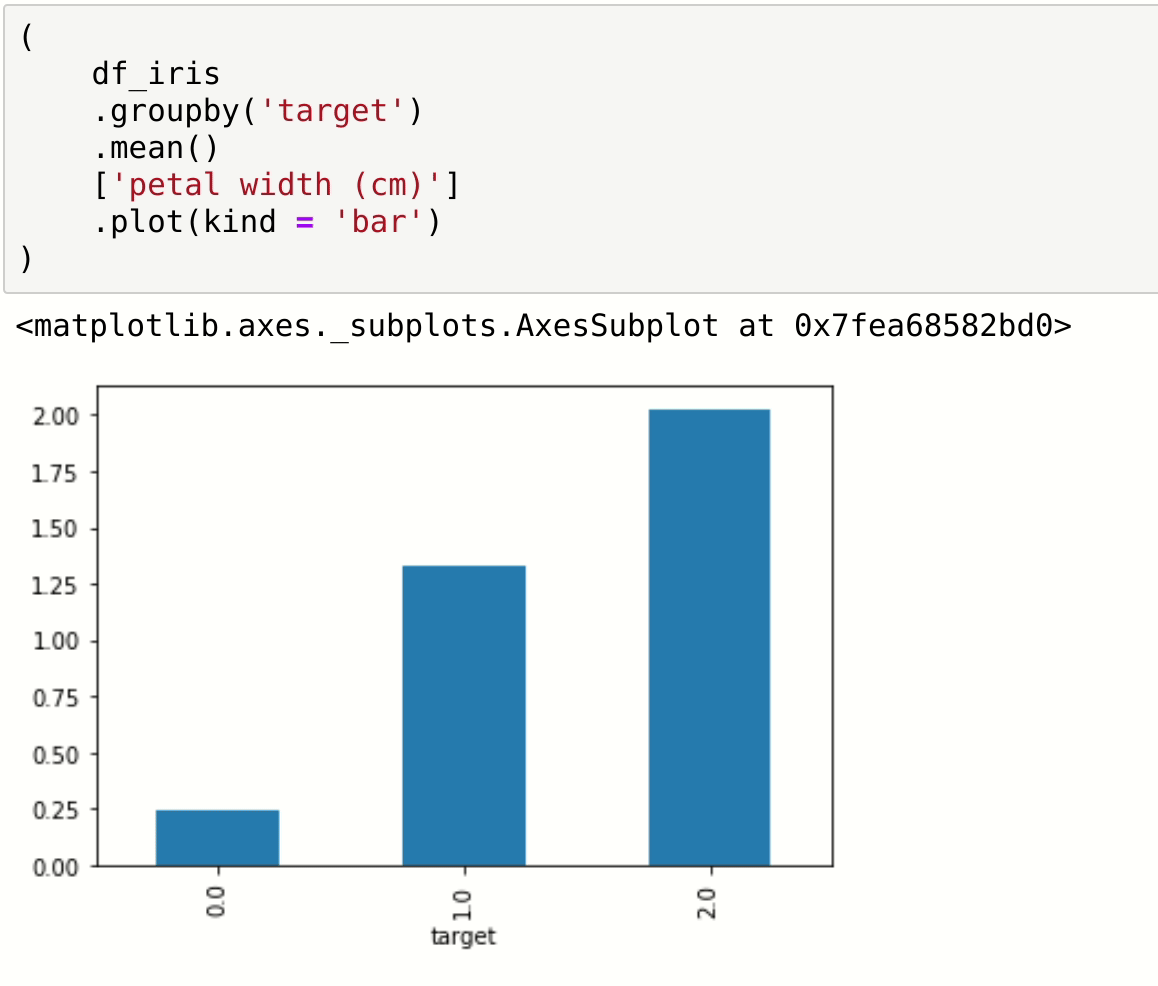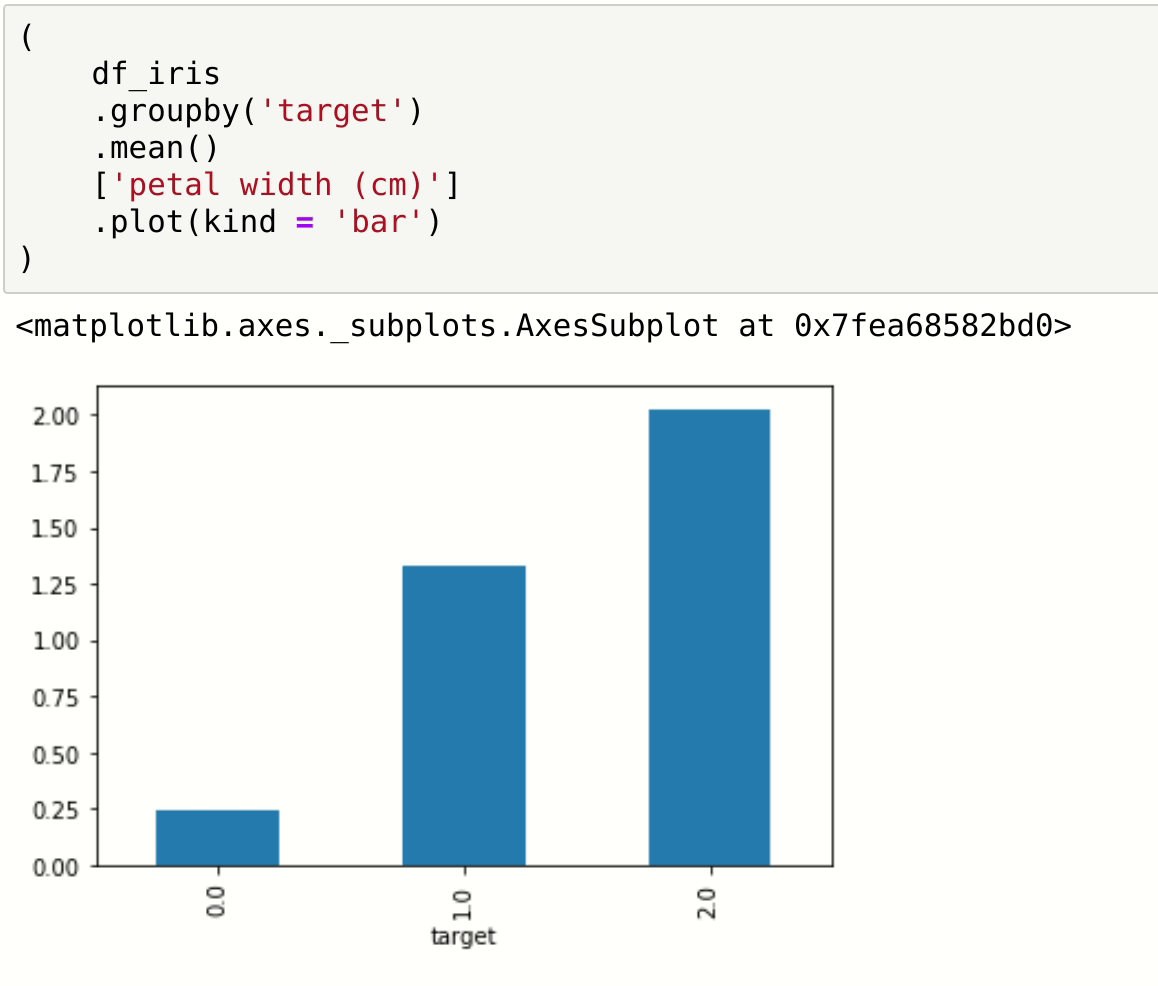
See how you start with the simple dataframe, and you built your desired result incrementally, observing every step? and how at the end of building it you have code that is easy to read? and how you can see intermediary steps? and how you avoid having intermediate dataframes with random names? and how …
When?
In every project you do.
Code formatting: Pylint and Black
What?
Pylint and Black make your code be in better shape. Black reformats your code and gives you "freedom from pycodestyle nagging about formatting. You will save time and mental energy for more important matters." Black deals with eg. having the right spacing all throughout your code. It will change the code leaving its functionality intact.
Pylint scans the code and flags potential ways to improve it, for example, show unused imports, show unused arguments in a function, marks duplicate code, etc.
When?
In every project you do.
How?
Install both of them in your virtual env. Run black, then run Pylint every time you finished a task (such as, for example, before a git commit) and your code will be magically better.
Tests: Pytest
What?
Tests allow you to ensure that your code is doing what it was intended to do, as you keep on developing and making changes to the whole project. For example, imagine you have a function that is intended to transform a dataframe, and you realize you can change the function to make it more time efficient. If you don have tests, you may inadvertently change the way your function works.
Pytest is a library that helps making assertions in order to verify a specific functionality in your repo, and make it easy to test the functionalities of your code when you deem it useful (such as, for example, before a git commit, and after code formatting)
When?
In every project you do.
How?
Install pytest in your virtual env. Create your test files as shown here, and off you go. Making a ci pipeline as shown here is a good way to integrate the benefits of tests and code formatting (and more!)
So that's about it. If you follow this practices, you will have a repo that:
- Facilitates collaboration
- Can be easily built upon
- Is easier to read and write by you and others
- Can be monitored
Hopefully this collection of topics can kickstart your way into building better code. Granted, this is actually not "everything" data scientists should know about software development, since other important topics are omitted, but I have to leave some stuff for part 2!