“The dealer always wins” is a typical saying in gambling. It reflects the fact that in most games of chance the house (e.g. the casino or the bookmaker) has a statistical advantage. In other words, assuming the betted amount is 1, the house has an expected return higher than 1, in contrast to the gambler who has an expected return smaller than 1. Therefore, if you visit the casino, most likely you will make a net loss in the long run.
Sports betting is no different. Both the bettor and the bookmaker can be equally skilled in predicting the outcome of a match, however the bookmaker sets the rules for the bet and thereby guarantee themselves a profit in the long run. The way they do this is by controlling what is called the payout.
Here is a quick example. Lets take two darts players who are equally skilled and thus objectively would both have a 50% chance of winning a head-to-head game. The bookmaker can set the odds, which we will define as O₁ and O₂ for player 1 and 2, respectively. For this particular game O₁ = O₂ = 1.90 would be reasonable odds. Meaning that for each $1 bet you get back $1.90 if you win. But what is the expected value of your return, X? Well if you bet $1 on a win for player 1, your expected return for this game is (remember that the win probability for each player is 50%):
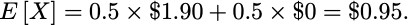
So in the long run, each dollar spent results in 95 cents return, and you will make a loss! I.e. the ‘payout’ the bookmaker sets for this game is 95%, meaning that the bookmaker will expect to make a profit of 5% over all bets, assuming they assessed the win probabilities correctly. So we see the odds the bookmaker set are not fair, fair odds would have been O₁ = O₂ = 2.0. Note that these odds also corresponds to equal winning probabilities for each player, namely P₁ = O₂/(O₁ + O₂)=0.5 and P₂ = O₁/(O₁ + O₂)=0.5.
In the remainder of this blog post we will focus on the specific game of darts, where games are head-to-head and results depend largely on the players’ skills. However, the discussion generalizes to other sports too.

What we have seen above is that bookmakers make a profit by controlling the payout. In order to do so they have to set the odds accordingly. For this, they need to know the probabilities. An omniscient bookmaker who gets all probabilities spot on cannot be beaten (in the long run). But bookmakers are not omniscient and therefore there are two ways in which they can be beaten, purely based on estimating the probabilities better.
In fact, strategy 1 is just a specific version of strategy 2. Nevertheless, even if you manage to predict each game more accurately than the bookmakers, you are unlikely to make a profit, since the bookmakers get pretty close to getting the probabilities right. This can be seen from Fig. 1, which shows that the bookmakers do a pretty good job at estimating the odds correctly for darts.
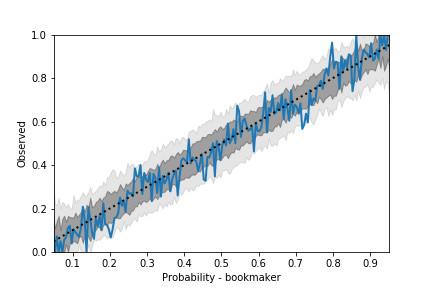
Fig. 1 illustrates that bookmakers assess the probabilities right on a large sample of games. But they could still be wrong on a number of individual games. Strategy 2, as outlined above, relies on identifying where the bookmakers misjudge the actual probability. For instance, in the unrealistic event where the bookmaker would offer equal odds, e.g. O₁ = O₂ = 1.90, in a match between reigning world champion Michael van Gerwen against the world’s number 94 our intuition already tells us we can likely make a profit by betting on van Gerwen. The goal is to identify all such games. However, since most of the time it is not easy to tell when the bookmakers are wrong, we can try to have a machine-learning (ML) algorithm do this for us.
For the purpose of this project we used darts statistics, including features such as averages, checkout percentages, number of 180s (maximum score with 3 darts) and head-to-head statistics. In addition, we used historic odds in order to assess whether this model could have made a profit.
First, to further motivate our tactics of only betting on a selection of games lets consider the benchmark accuracies. If we would always bet on the player with the highest win chance according to the bookmakers we achieve an accuracy of 70%. Constructing a skill-rating based solely on the results of matches gets to 69% accuracy on the same data. When training a machine learning model, like a random forest, boosted tree or fully-connected neural network with carefully constructed features and optimized on a binary-cross entropy loss function we also got to 70% accuracy. Clearly we are not outperforming the bookmakers, so there is little chance to make a profit.
The binary-cross entropy loss function optimizes our ability to predict the outcome of games correctly, i.e. it optimizes the accuracy with which we predict games. However, that is not our goal. What we want is to identify the games where the bookmaker misjudges the true probability and thus offers favourable odds. I.e. we want to optimize our return-on-investment. Below is a loss function constructed to do exactly this.

The custom loss function contains two elements, the terms between square brackets are the returns if we bet $1,- on player 1 or 2, respectively. Note that this depends on the outcome of the game (yᵢ), if we get it wrong we loose our money. The ReLu function contains our betting strategy. It has the property that Relu(x) = 0 when x ≤ 0 and Relu(x)=x otherwise. The argument is our expected return: the odds multiplied by our estimated win probability minus 1. Given the properties of the ReLu function this means that it is only larger than 0 if we believe the odds are favourable for us. In other words, if our model believes the odds are unfair, it won’t bet any money. On the other hand, the more favourable the odds appear, the higher the amount the model will bet.
This loss function ensures that what we are optimizing is not how well we can predict the outcome of a game, but rather our winnings. Note that as a consequence of our custom loss function, the predicted probabilities are not representative of the true probabilities, since when the model thinks the bookmakers are off it will push the probabilities towards the extremes (0 or 1) in order to bet more.
In order to test our model performance we constructed a densely-connected neural network with two hidden layers. The final layer is a sigmoid layer that predicts the probability of player 1 winning. Using the bookmaker odds and the outcome of the game we then compute the loss with the custom loss function described above. All of this is implemented in PyTorch.
Since this is a time-series, the model is trained on historical data up-to a given point and subsequently applied to the next 50 games. This process is then repeated for the next 50 games, etc. Results are shown in Fig. 2.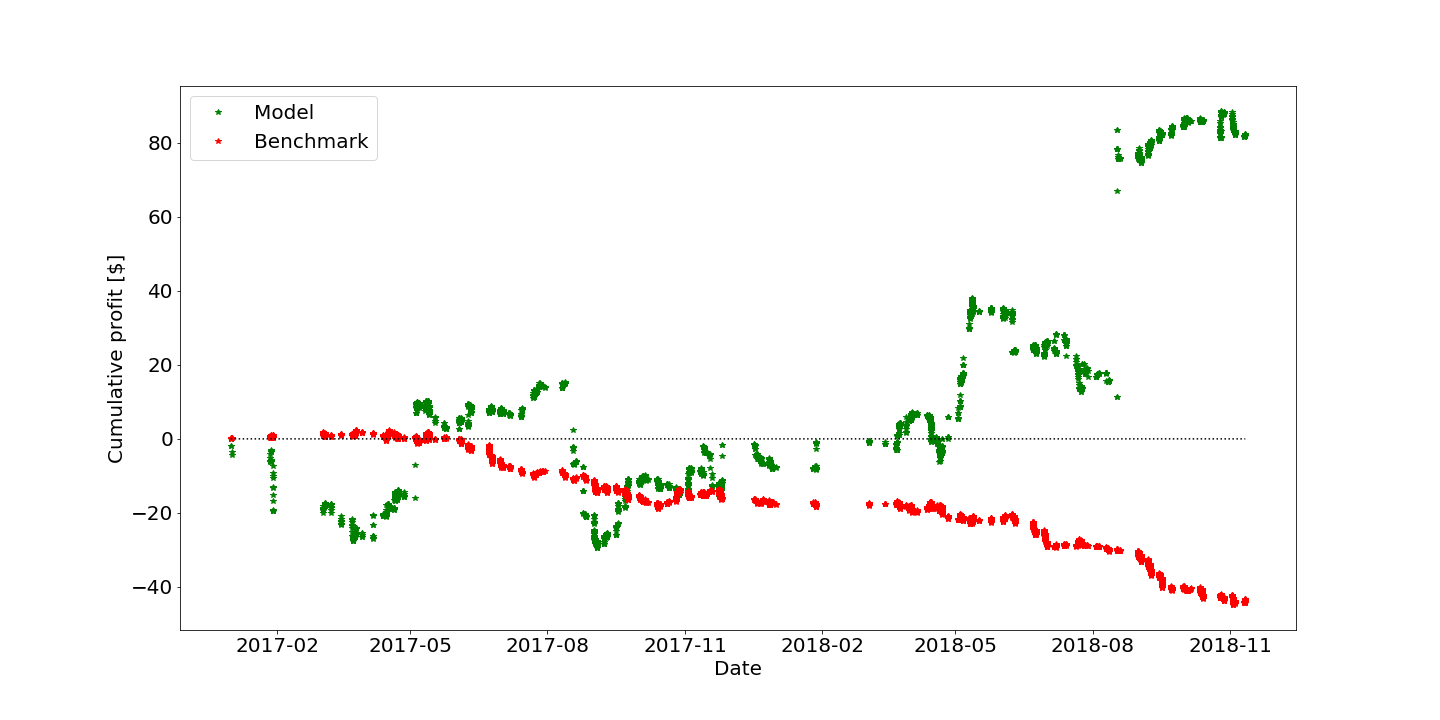
Our model managed to a make a profit, albeit with large fluctuations over time. It suffered from a few major losses, but also made some major winnings compensating the losses. In the end the return on investment was about 10%. As a benchmark we took a strategy where we always bet on the player that is most likely to win according to the bookmaker (which would not be very different from a model where we optimize using binary cross-entropy to predict the winner). Since the odds are unfair, we make a loss of about 5% in the long run.
Thanks to Guido Tournois with whom I collaborated on this project.